原理说明
大家好,欢迎收看本期教程,今天我们要来聊聊模型的作用,以及怎么才能用好模型。在这之前,老规矩,让我们了解更多的基础知识,毕竟打好基础才能学得更快更好嘛。
扩散模型
上次讲到了一个很重要的概念,叫做diffusion,中文叫扩散。这个概念很简单,就是图片从模糊变成清晰的过程。我们可以来看一下演示图:先把一张图片加上很多噪点,让它变得像电视里没有信号的那种画面。然后再让AI逐渐去掉噪点,让图片恢复原貌。这个过程就是diffusion。
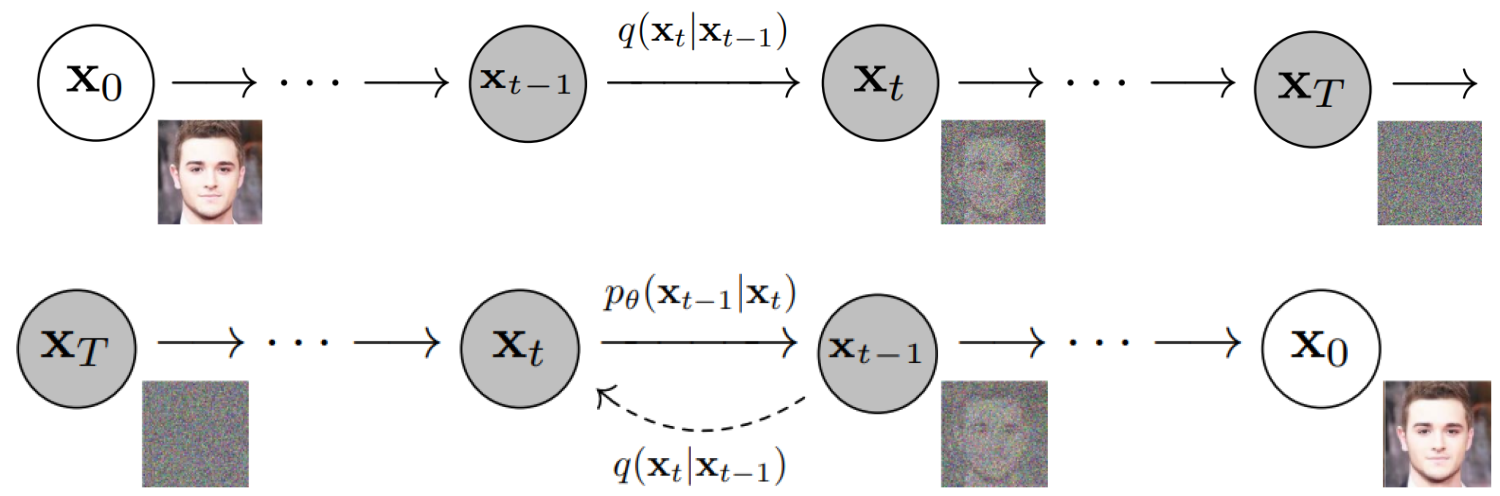
当然实际情况肯定不是这么简单,这里面还有很多细节和技巧,但是我们今天不需要深入去了解,只要掌握这个概念就够了。如果大家有兴趣想了解更多,可以在弹幕里留言,点赞支持,如果反响热烈的话我会再出一期视频专门分析一下diffusion论文。

潜在空间
好了,现在我们来说说第二个概念,叫做latent diffusion,中文叫潜在空间扩散。这个概念可能听起来有点高深,但其实也不难理解。
大家要知道AI绘画其实非常耗费计算资源,因为它要处理的图片数据非常庞大。比如说,如果要画一副512*512的图像(这已经算是比较小的图像了),计算机需要针对512*512*3的维度进行运算,这里的3是因为每个像素点都由红、绿、蓝三个颜色组成。这样庞大的运算通常需要上百台显卡配合使用。
那么有没有什么办法可以减少运算量呢?latent diffusion论文就提出了一个很巧妙的办法。
它的思路是这样的:其实人眼看照片时候普通和超高清都能识别其中的角色是什么,会忽略很多细节。但是对于计算机来说这些细节都是要进行计算的。如果我们能够把这些无关紧要的细节去掉,就可以极大地提升训练速度,而且生成的图像也能满足我们的要求。
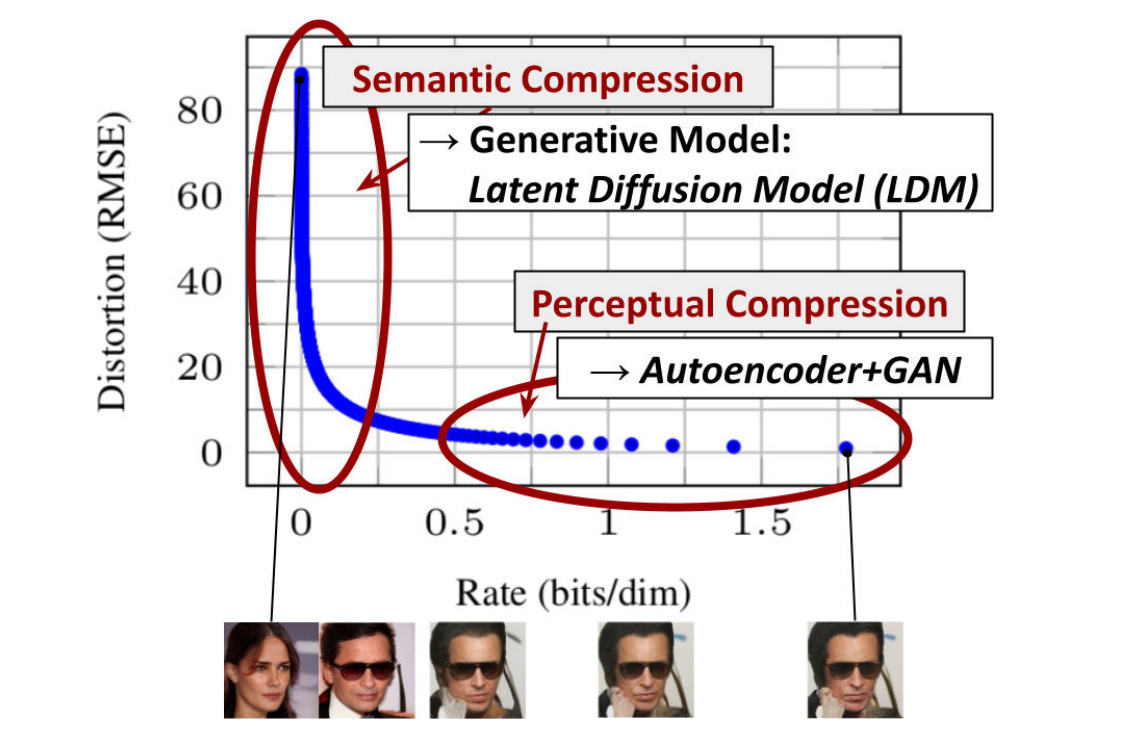
可以看到论文上的这张曲线图,当图片精细度超过这个点之后其实对我们来说提升并不大,但是对于计算机来说承担的运算量是成倍增加的,低于这个点呢我们就会逐渐无法识别图片,但是运算量也就减少了一点点。所以我们就要找到一个平衡点,保证图片的清晰度,同时也要最大程度减少计算量。
为此就提出了一个概念叫做潜在空间(latent diffusion)。潜在空间就是一种特殊的空间,它可以用一些数字来表示图片的特征,比如颜色、形状、大小等等。这些数字就像是图片的身份证,可以唯一地区分不同的图片。潜在空间的好处是,它可以用很少的数字来表示图片特征,这样就可以大大减少运算量,提高效率。
我们可以用一个简单的例子来理解潜在空间。比如说,我们个一维空间用腿走路的数量比如人、猴子、大猩猩两条腿的就分类在一起了,小狗,小猫,大象,长颈鹿四条腿的就在一起了。
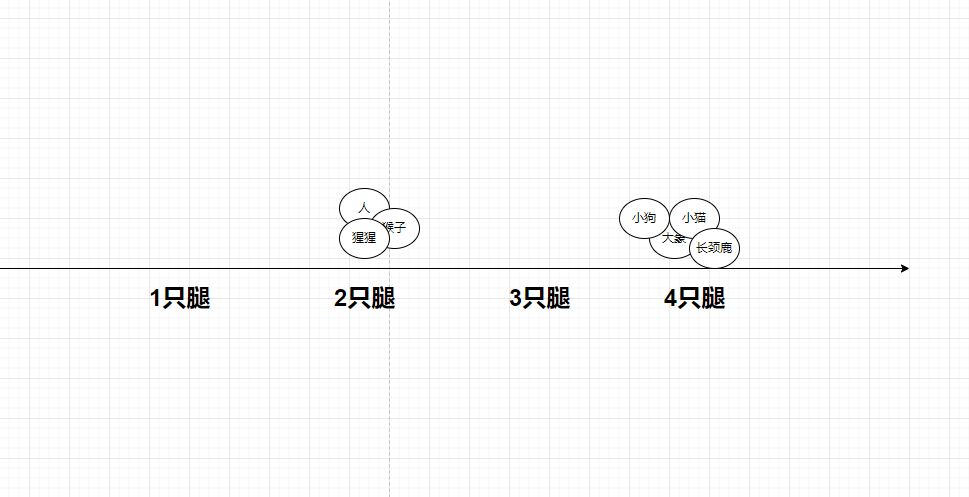
再加上身高的维度,变成二维的,猴子比人矮一点,大猩猩和人差不多高可以放到一起,小狗和小猫差不多这个位置,大象这里,长颈鹿这里。是不是分类又细致了一点?我们还可以加上毛发、脸部特征、姿势等等维度,以此在潜在空间标注出来不同动物所在区域。
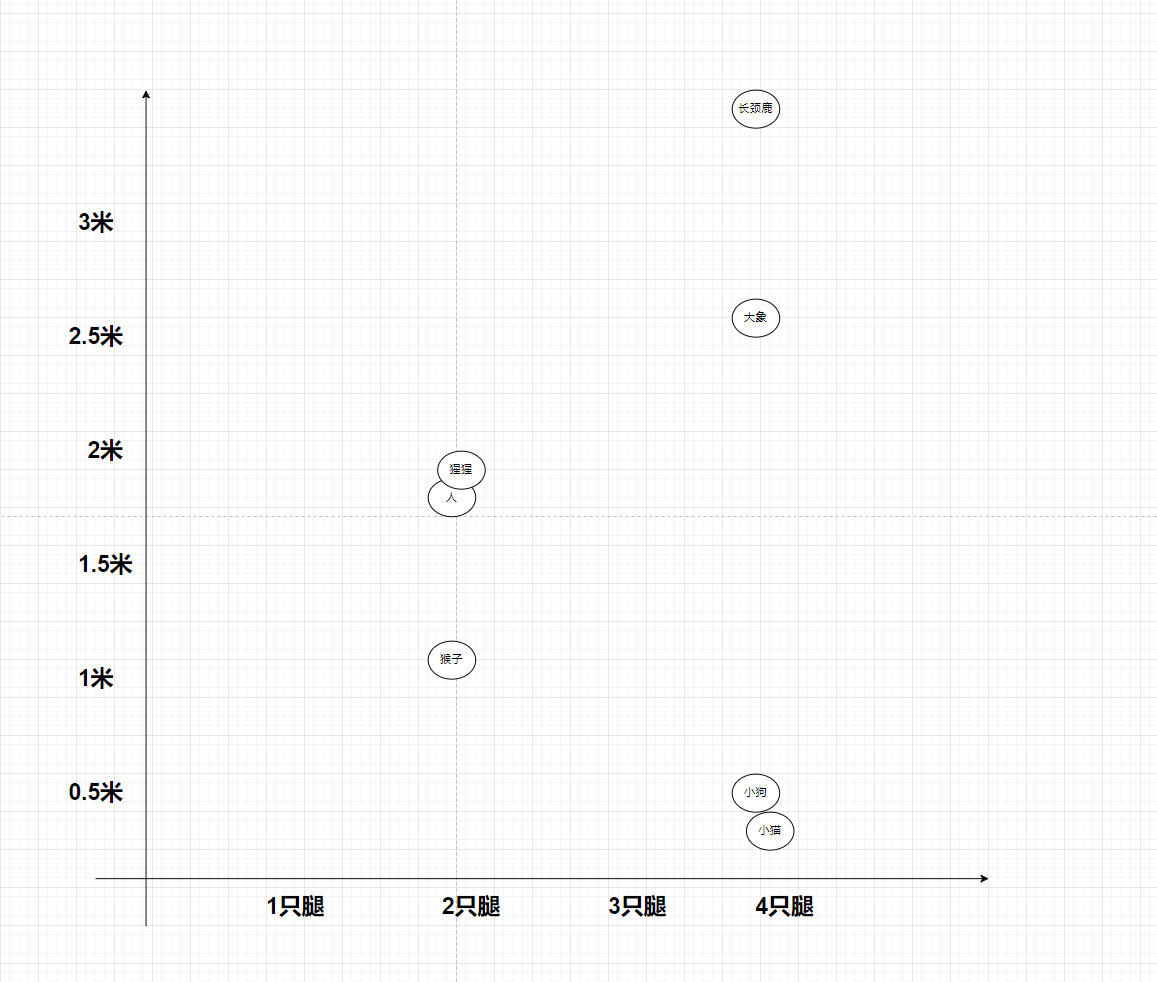
那么反过来如果一个东西看起来像苹果,摸着像苹果,味道像苹果。我们就可以认为这就是一个苹果。AI在潜在空间也是如此处理的,只要依靠潜在空间的特征值画出来的图片,我们就可以认为是这个动物的图片。它能摒弃大多数我们人类无法识别的特征,压缩到低纬空间,然后再通过特征进行绘画,就能快速有效的画出我们能够识别的图像呢。
文字与图形关联
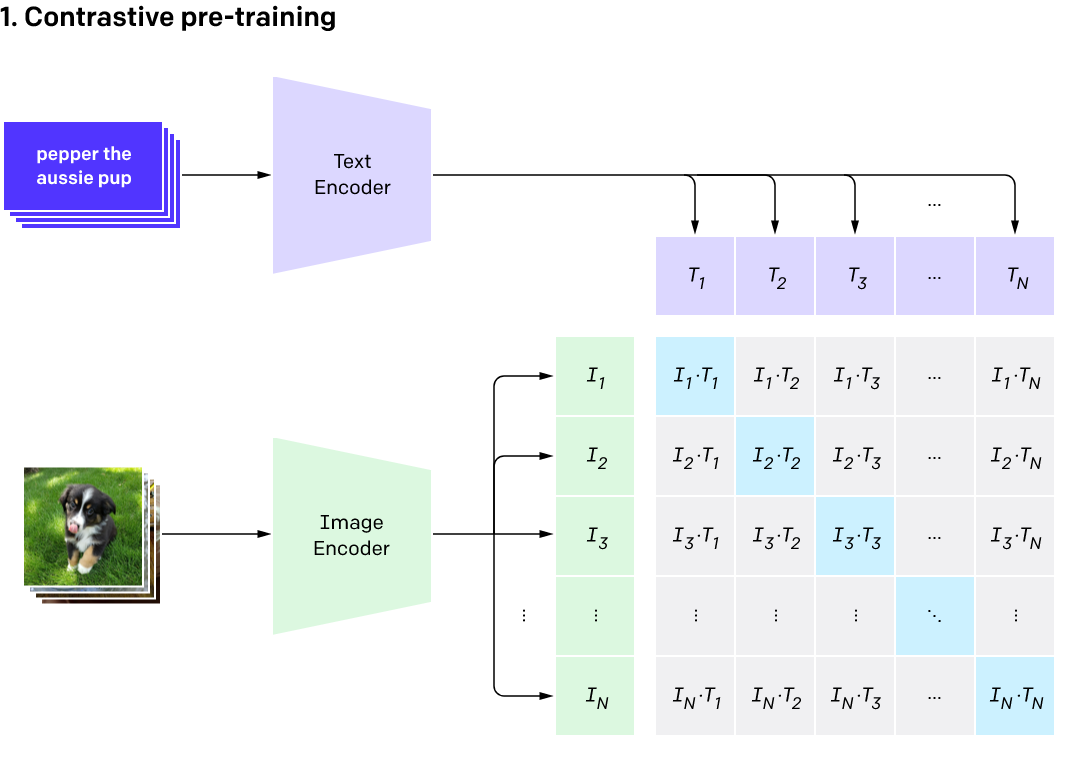
画图解决了,但如何把文字与图片关联在一起呢?这就跟我们小时候做连线题一样,将文字与图片的潜在空间关联起来,这样我们就能通过文字找到图片,也能通过图片找到文字。如果不理解这个过程也没关系,我们只要知道通过文字能够找到图片的潜在空间,再通过图片的潜在空间进行作画就可以了。
总体架构
这张图就是stable diffusion的基本框架。大致分为三个步骤:
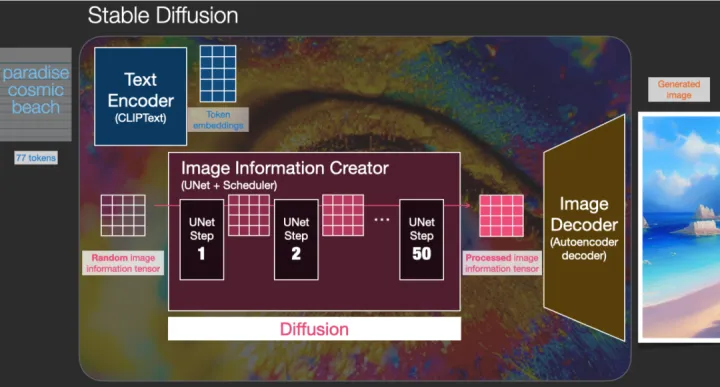
第一步就是提示词分析,也就是Text Encoder,CLIP它可以将我们输入的文字转化为计算机可理解的语义向量。
第二步就是latent diffusion的过程,将词向量转换为潜在空间数据,然后通过不断地去噪迭代生成图片。但是这时候生成的图片其实只是潜在空间的图片,是不可用的。
还需要第三步就是将潜在空间的图片转化为我们所见的图片,Image Decoder,Vae模型就作用在这里了。
模型介绍
模型区别
在介绍了一些基础知识之后,我们来看看不同的模型都有什么用。
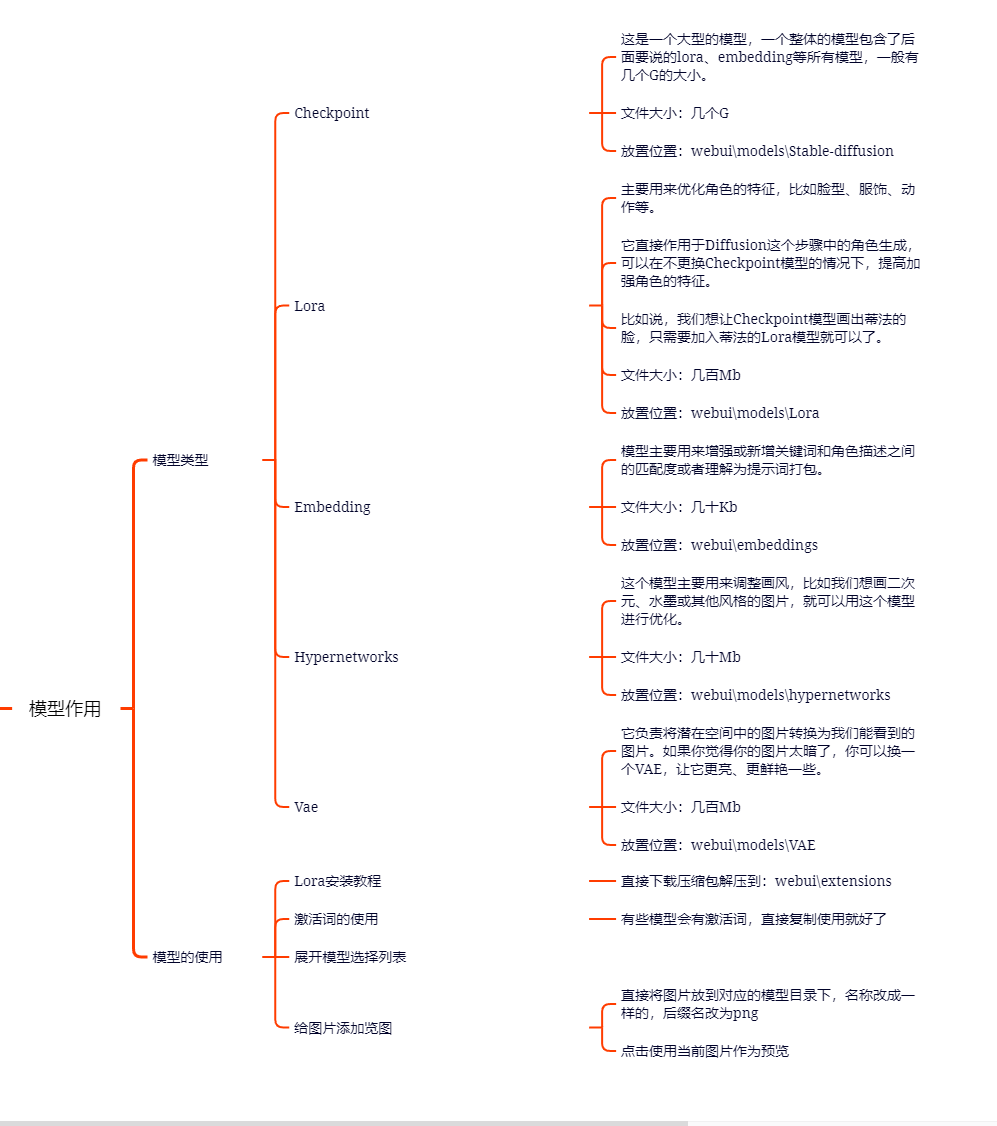
首先是Checkpoint模型,这是一个大型的模型,一个整体的模型包含了后面要说的lora、embedding等所有模型,一般有几个G的大小。
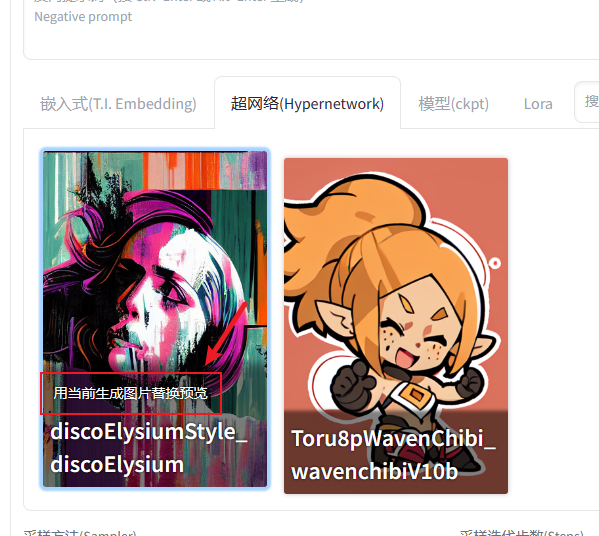
然后是常用的Lora模型,这是一个小型的模型,只有几百MB,主要用来优化角色的特征,比如脸型、服饰、动作等。
它直接作用于Diffusion这个步骤中的角色生成,可以在不更换Checkpoint模型的情况下,提高加强角色的特征。
比如说,我们想让Checkpoint模型画出蒂法的脸,只需要加入蒂法的Lora模型就可以了。

接下来是Embedding模型,这个模型主要用来增强或新增关键词和角色描述之间的匹配度或者理解为提示词打包。假设我们想画一副极具特色的比如这张罗宾图,我们可能需要添加很多关键字比如蓝色的头发,头顶着太阳眼镜,穿着蓝色外套等等。引入此模型后使用关键字robin_v2_1600就能生成这样的画像

那么我们就可以加入Embedding模型,让它更准确地画出我们想要的角色,说白了让关键字和角色关联度更高,或者定义一些而外的关键字与角色的关系。
最后是Hypernetworks模型,这个模型主要用来调整画风,比如我们想画二次元、水墨或其他风格的图片,就可以用这个模型进行优化。
前面三个模型都是作用于Diffusion中的绘画过程,如果属于Checkpoint属于大脑,这几个模型就是外接大脑。
最后一个步骤是VAE,它负责将潜在空间中的图片转换为我们能看到的图片。如果你觉得你的图片太暗了,你可以换一个VAE,让它更亮、更鲜艳一些。

这里有总结了各个模型的区别,如果记不住你可以截图保存一下,用的时候拿出来看下。
模型下载与安装
模型使用只需要把它下载后放到相应的位置就可以了。
你可以在C站点击筛选按钮,然后选择你要搜索的模型类型,就可以找到你想要的模型了。
然后按照模型的位置安放。
放好了之后我们点击这个按钮,打开模型选择列表,刷新一下就可以看到了。
模型的使用
lora插件的安装
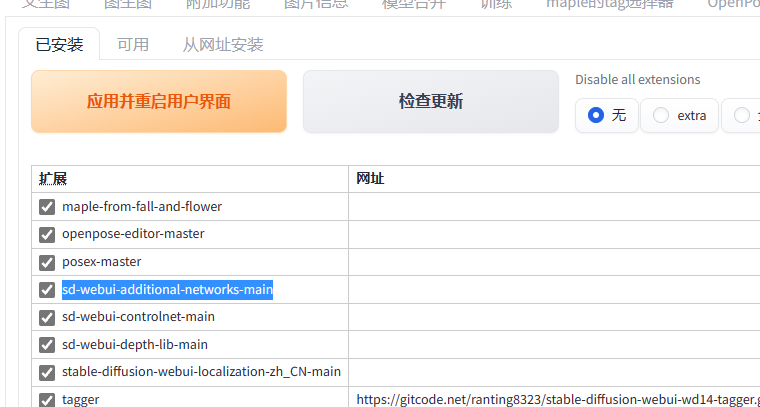
lora模型使用我们需要安装一个而外的插件,直接webui目录直接git clone或者直接github下载一个压缩包,然后解压到插件目录就可以了,插件目录:webui\extensions
# git clone命令
git clone https://github.com/kohya-ss/sd-webui-additional-networks.git extensions/sd-webui-additional-networks
然后再回到webui前端扩展中勾上sd-webui-additional-networks-main点击应用并重启
使用的时候打开模型选择窗口,选择你需要的模型,然后点击生成图片就可以了。
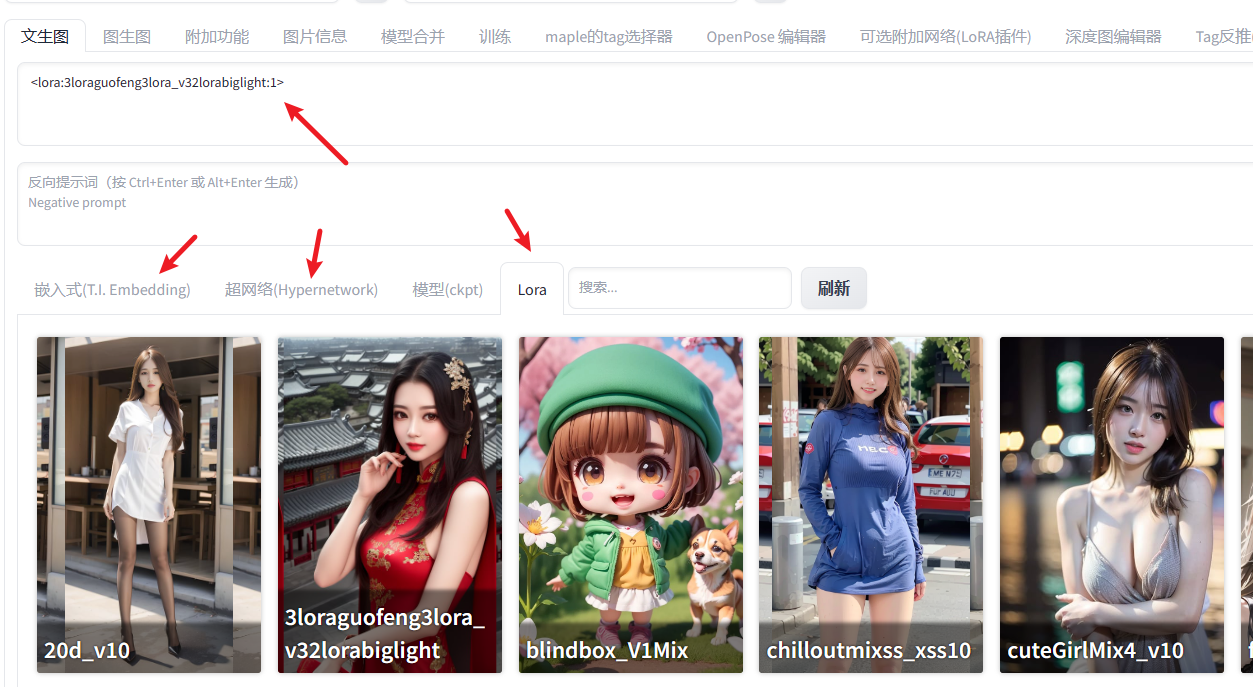
embedding是加入关键字,lora和hypernetwork后面这里这个数字就是模型的强度,数字越大,模型的权重就越大,建议0.1~1之间。
大家可以看到我的模型都有示例图片,这样你就可以直观地看到效果了。如果你也想给你的模型加上示例图片,很简单,只需要找到模型所在的位置,然后把图片放进去,把文件名改成和模型一样的就行了,文件后缀要改为png。
如果你想用生成的图片作为示例图呢,点击这个应用当前图片作为示例图就可以了。